



Résumé :
• La prolifération des données personnelles doit être accueillie avec optimisme. Elle permettra d’améliorer la condition des êtres humains dans une multitude de secteurs d’activité.
• Le marché du traitement des données personnelles ne comporte pas de déséquilibres commerciaux particuliers. Son succès et les études marketing révèlent au contraire que les services numériques financés en contrepartie de l’accès aux données personnelles des internautes génèrent une valeur inestimable pour ces derniers. Les services en question sont beaucoup plus valorisés que la vie privée concédée.
• Il est de la responsabilité des utilisateurs de s’informer sur le fonctionnement des plateformes, quitte à le faire au travers des leaders d’opinion, des vulgarisateurs ou d’autres tiers de confiance pour pallier les obstacles que la technicité des conditions d’utilisation fait peser sur leur compréhension.
• Les gouvernements doivent se contenter d’abolir les restrictions à la libre circulation et à la libre exploitation des données. Les efforts de l’Union européenne pour abolir les restrictions à la localisation et au transfert des données au sein de ses frontières doivent être salués. L’Union européenne doit cependant résister à la tentation de reproduire un protectionnisme numérique à ses frontières.
• Les réglementations relatives à la protection de la vie privée restent les obstacles les plus redoutables au déploiement d’une économie compétitive fondée sur les données. Avec sa réglementation, l’Europe nuit à sa compétitivité et risque de manquer la révolution des données. Nous proposons de remplacer la réglementation par une logique contractuelle où les normes de confidentialité seraient édictées par la libre-confrontation des producteurs et des consommateurs sur un marché libre des services numériques.
• Les missions des autorités de contrôle doivent être revues. La CNIL doit être privatisée pour devenir un tiers de confiance de droit commun opérant sur un marché de l’audit et de la certification des politiques de confidentialité ouvert à la concurrence. Ces tiers de confiance pourront vendre leurs services aux organisations qui opèrent sur des secteurs où il existe une véritable demande pour réduire les asymétries d’information et renforcer la confiance des utilisateurs vis-à-vis du traitement des données opéré par les entreprises.
Introduction
Beaucoup considèrent les données comme le pétrole du XXIe siècle. Sans doute vont-elles, comme l’or noir, profondément transformer nos civilisations. Mais il existe une différence fondamentale entre les ressources minérales, comme le pétrole, et la donnée que le Larousse définit comme « une représentation conventionnelle d’une information en vue de son traitement informatique ». Contrairement à la plupart des biens corporels et incorporels, les données ne sont pas soumises à cette imperfection qu’est la rareté. Elles sont par essence abondantes.
Leur usage et leur exploitation excluent toute rivalité. C’est-à-dire qu’une même donnée peut être traitée et exploitée simultanément par une infinité de personnes sans que l’activité de l’une entrave celle de toutes les autres. L’information est une ressource inépuisable. Cet aspect inépuisable couplé à sa publicité tend à lui conférer le caractère de « bien public » selon la définition de l’économiste américain Paul Samuelson. L’abondance de l’information et la démocratisation des nouvelles technologies de l’information et des communications (TIC) expliquent le volume colossal des données produites par l’humanité depuis plusieurs années.
Selon certaines estimations, la quantité d’informations disponible représentait en 2013 entre 1200 et 4400 exabytes. 98% de cette information serait numérisée. S’il fallait attribuer une portion de cette information à chaque personne vivante sur Terre, chaque individu percevrait au minimum 320 fois l’information jadis contenue dans la bibliothèque d’Alexandrie[[Pour les estimations les plus conservatrices, voir l’ouvrage intitulé « Big Data: A Revolution That Will Transform How We Live, Work and Think » de Kenneth Cukier et Viktor Mayer-Schoenberger,]]. Selon l’International Data Corporation, ce volume pourrait atteindre 44 000 exabytes en 2020[[The Digital Universe of Opportunities: Rich Data and the Increasing Value of the Internet of Things, International Data Corporation, April 2014]].
C’est ce volume, qui dépasse l’entendement et qui croît de manière exponentielle, qu’il convient d’appeler le « Big Data ». Bien sûr, l’écosystème numérique aussi « virtuel » puisse-t-il être, n’est pas totalement affranchi des contraintes matérielles. Tout d’abord, la production d’un tel volume de données aurait été impossible sans la diffusion massive d’appareils électroniques connectés toujours plus performants (des capacités de calcul et de stockages plus grandes) et moins chers, conformément aux prédictions de l’entrepreneur Gordon Earle Moore, même si celles-ci sont de moins en moins vraies[[« The End of Moore’s law », The Economist]].
Le traitement d’un tel volume de données nécessite d’ailleurs le support de lourdes infrastructures informatiques. C’est pourquoi les entreprises des technologies de l’information tendent à dépenser de plus en plus pour bénéficier des services des centres de données.

Dépenses de l’industrie des nouvelles technologies de l’information en services de centres de données à l’échelle mondiale
L’industrie du Big Data est cependant frappée d’un paradoxe susceptible de compromettre son développement. Tandis que la profusion de richesses et de ressources est habituellement bien accueillie, la quantité illimitée d’informations ainsi que la capacité grandissante à les traiter pertinemment génère des inquiétudes.
Les données amassées par l’industrie du numérique font craindre un usage abusif de celles-ci. En réaction, les États se dotent de législations restrictives pour raréfier les données en limitant les possibilités de traitement informatique. Les entreprises du numérique soulèvent également des inquiétudes d’ordre économique et politique. À titre d’exemple, le très influent magazine The Economist estime que des firmes comme Google, Facebook et Amazon constituent, du fait de leur taille et de leurs parts de marché, une menace pour l’équilibre concurrentiel et les libertés publiques.
C’est pourquoi les propositions se multiplient pour règlementer l’industrie du traitement des données. Certains proposent d’appliquer plus sévèrement la législation anti-concentration ou encore de contraindre les entreprises à divulguer à leurs concurrents des informations dont la rétention exclusive leur confère un avantage compétitif (droit à la portabilité)[[« How to tame the tech titans », The Economist,]]. D’autres proposent d’octroyer aux internautes un droit de propriété à géométrie variable sur leurs données personnelles[[Voir notamment le rapport de Génération Libre « Mes datas sont à moi. Pour une patrimonialité des données personnelles ».]]. Le Règlement général sur la protection des données (RGPD) qui doit entrer en vigueur le 25 mai 2018 s’inspire de ce climat de défiance.
Face aux inquiétudes et au data scepticisme, cette étude tentera de dissiper les principaux mythes sur la dangerosité de l’industrie du Big Data. Elle rappellera également les opportunités commerciales qu’offre un usage libre des technologies de l’information et de la communication. Sans négliger la nécessité de favoriser un environnement institutionnel propice au développement d’une industrie compétitive du Big Data, la présente étude analysera les principaux obstacles à la libre exploitation des données à démanteler. Enfin, sans nier les attentes légitimes des utilisateurs en matière de vie privée, nous montrerons que l’existence de standards ambitieux en matière de confidentialité et de sécurité des données personnelles peut s’envisager en l’absence de législation et de réglementation étatiques, dès lors qu’ils correspondent à une véritable demande de la part des consommateurs de services numériques.
I – Le fonctionnement du commerce du traitement des données
Parler de commerce ou de marché des données est en soi un abus de langage, tant la valeur d’une information brute est quasi-nulle dès lors qu’elle est publique. Au regard de l’analyse économique et indépendamment des distorsions induites par la législation, seuls les biens et les services utiles et rares sont susceptibles d’être valorisés et de faire l’objet d’un commerce. Tout comme l’air est difficilement marchandable (pourquoi payer pour une ressource disponible en abondance ?), une information en elle-même ne vaut pas grand chose, en particulier quand elle est multipliable à l’infini et publiquement accessible. Cela explique par exemple les difficultés que connaît l’industrie de la presse depuis l’arrivée d’internet, qui a permis la diffusion massive d’information à un coût dérisoire. Et a donc entraîné une chute brutale de valeur des services de presse. Ce n’est donc pas tant l’information qui fait l’objet d’un commerce mais le service plus rare et non moins utile qui consiste à la divulguer, la collecter, la transmettre, la conserver, l’enregistrer, l’organiser, la structurer, la protéger… Autrement dit, seul le service qui consiste à traiter l’information a de la valeur et peut faire l’objet d’un commerce. L’industrie du Big Data peut donc se définir comme l’ensemble des activités commerciales qui reposent sur le traitement d’une vaste quantité d’informations pour servir des finalités particulières (publicitaires, marketing, médicales, scientifiques, etc.).
+Étude de cas : le duopole Facebook-Google sur le marché de la publicité en ligne+
La plus connue et la plus controversée de toutes ces finalités est celle en lien avec le secteur de la publicité et du marketing, notamment en ligne. Un secteur de plus en plus dominé par le duopole Google – Facebook (Figures 2 et 3).
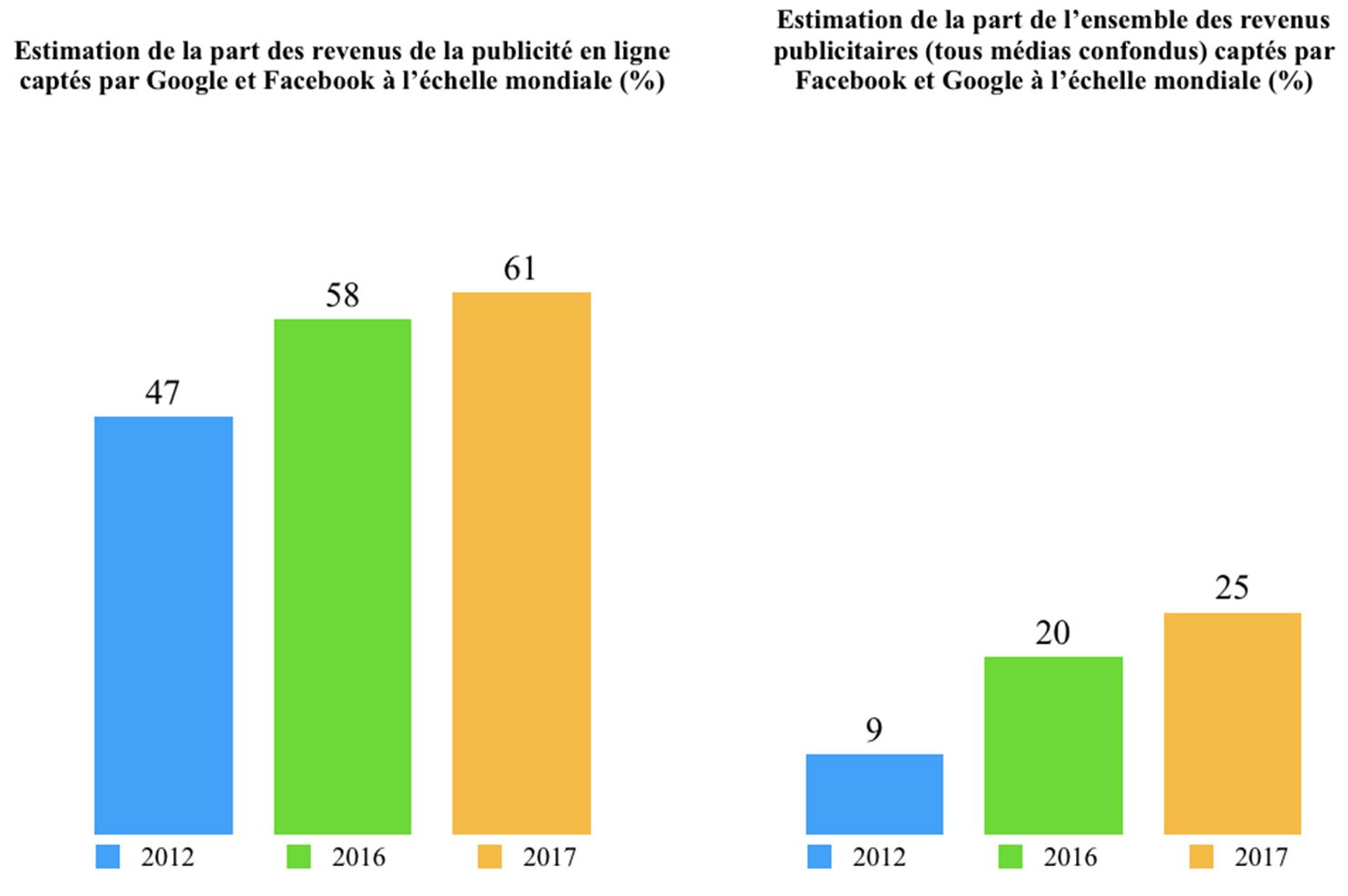
En 2016, le chiffre d’affaires de Google et de Facebook représentait respectivement 90 milliards et 27 milliards de dollars[[Source : Nasdaq]]. Pour le premier réseau social mondial qui compte un peu plus de 2 milliards d’utilisateurs, la publicité représente 97% de son chiffre d’affaires[[Facebook annual report, 2016]]. Pour Google, elle couvre 88 % de ses revenus[[Alphabet annual report, 2016]]. La publicité ciblée constitue donc le coeur du modèle d’affaires de ces deux géants du net, lesquels sont des modèles de marchés « bi-faces ». Ces plateformes fonctionnent en se positionnant comme des interfaces entre deux types de clientèles bien distinctes : les annonceurs et les internautes. Mais certains assimilent les modèles d’affaires de ces plateformes à une prédation qui s’exercerait sans vergogne au détriment de l’utilisateur. Ce dernier verrait ses informations pillées sans contrepartie significative[[Pierre Rimbert, « Données personnelles, une affaire politique », Le Monde Diplomatique, Septembre 2016]]. Au-delà de la consonance anti-capitaliste d’un tel discours qui conçoit les transactions avec les géants du Net comme un jeu à somme nulle, il méconnaît le fonctionnement du marché du traitement des données.
Prenons l’exemple d’une entreprise comme Facebook. Son modèle d’affaire peut s’illustrer de la manière suivante :

Schéma des transactions de Facebook
Ce même schéma peut être utilisé pour de nombreux autres services comme Google, mais aussi pour les multiples sites d’information. On le voit ici, l’idée même que le marché du traitement des données serait fondé sur des concessions unilatérales est erronée, tant du point de vue des plateformes que de celui des utilisateurs. Sous-entendre, comme le fait Facebook, que la mise à disposition de son réseau social serait un acte à titre gratuit suscite des doutes sur l’exactitude des conditions de vente. Tout le problème vient de la définition étroite de la « gratuité » qui sous-entend que seule une compensation pécuniaire pourrait s’apparenter à un prix.
Or un prix n’est ni plus ni moins qu’un ratio d’échange. Il peut faire appel à des éléments pécuniaires et non-pécuniaires. Si un commerçant propose d’échanger 10 pommes contre deux bananes, alors il faut en déduire que le prix d’une banane correspond à 5 pommes et inversement. De la même manière, lorsqu’un employeur propose de louer les services d’un salarié contre 2000 euros ainsi que d’autres avantages non pécuniaires (logement, conditions de travail, garantie d’un niveau de sécurité de l’emploi), cela revient exactement à intégrer ces avantages dans le prix du travail fourni par le salarié.
Ce raisonnement est applicable au marché du traitement de l’information. Plutôt que d’interpréter la mise à disposition de plateformes sans contreparties pécuniaires comme un acte à titre gratuit, il faudrait prendre conscience que les relations qu’entretiennent les utilisateurs avec les plateformes relèvent de rapports marchands tout à fait classiques. La contrepartie du service rendu par la plateforme n’étant pas ici une compensation pécuniaire mais bien l’accès aux données personnelles de l’utilisateur, cet accès ayant une valeur importante aux yeux de l’entreprise qui collecte ces données.
Pour s’en convaincre, il suffit de constater que des entreprises comme Facebook et Twitter refusent l’accès à leurs plateformes respectives à tout utilisateur qui n’accepterait pas de payer le prix demandé (l’accès à certaines données), par exemple en restreignant l’usage des cookies à l’aide des fonctionnalités présentes sur un navigateur internet. Pour l’utilisateur, la divulgation de ses données personnelles n’est donc ni plus ni moins que le prix à payer pour accéder aux services du réseau social, bien que certaines entreprises offrent la possibilité aux utilisateurs d’échapper à ce prix. C’est notamment le cas de Google qui ne restreint pas l’accès à son moteur de recherche à ceux qui auraient fait le choix de désactiver l’usage des cookies au travers des paramètres de leur navigateur.
+Une relation commerciale déséquilibrée ?+
Sans nier l’existence d’une transaction entre les plateformes et leurs utilisateurs, certains auteurs soutiennent que celle-ci ne peut être que déséquilibrée. L’opacité du traitement[[Hirsch, D. D., Law and policy of online privacy: regulation, self-regulation, or co-regulation. The Seattle Univ Law Rev., 34, 439, 2010]], les asymétries d’information[[Solove, D. J. (2004). The digital person: Technology and privacy in the information age. NYU Press]], l’insouciance des internautes, le pouvoir de négociation des plateformes ainsi que la longueur et la technicité des conditions d’utilisation et des politiques de confidentialité conduiraient systématiquement à une collecte excessive des données personnelles. À défaut d’être mieux rétribué, l’internaute paierait un prix bien plus élevé que dans le cas où nous nous situerions dans un marché qui fonctionnerait « parfaitement ». Autrement dit, un marché où chaque internaute saurait exactement la nature, la quantité des données collectées et la finalité de leur traitement. Cela se traduirait par des profits démesurés pour les entreprises du Big Data et une perte excessive de vie privée pour les utilisateurs. Ce raisonnement pose problème pour plusieurs raisons.
Contrairement aux mythes répandus, toutes les grandes firmes du numérique n’entretiennent pas le même rapport avec le profit. L’exemple de ces entreprises emblématiques que sont Facebook, Twitter et Google illustre la disparité des situations financières qui affecte les entreprises du secteur.
")
Situation financière de Facebook, Twitter et Google (2015 – 2017)
Quand bien même les profits de ces firmes seraient infiniment plus importants, leur existence même indique que les utilisateurs valorisent beaucoup plus leurs services que l’accès à leurs données, sans quoi il n’y aurait pas de transaction. Il n’est par conséquent pas pertinent de parler de transaction déséquilibrée dans la mesure où seul un échange librement consenti peut révéler l’équilibre d’une relation commerciale. Le fait que toutes les parties ne retirent pas les mêmes avantages d’un échange ne compromet pas la nature mutuellement bénéfique de la transaction.
S’il est impossible de mesurer le bien-être et le coût (notions subjectives) générés par l’accès aux plateformes mises à disposition des entreprises du net en contrepartie des données personnelles, certaines méthodes permettent d’avoir une idée de la valeur qu’un utilisateur attribue à ces services. Par exemple, le « surplus du consommateur » constitue la différence entre ce qu’un consommateur serait prêt à payer au maximum pour un service et ce qu’il paie effectivement pour en bénéficier. Le calcul n’est évidemment pas parfait pour plusieurs raisons. Il existe régulièrement un écart entre ce qu’un individu dit vouloir faire et ce qu’il fait effectivement. De plus, le prix de certains services numériques n’est pas toujours exprimé en unités monétaires, ce qui rend leur évaluation plus difficile. Enfin, l’impossibilité de déterminer précisément à priori les élasticités-prix fait qu’il est souvent hasardeux de chercher à anticiper le comportement des consommateurs.
Mais la notion de surplus de consommateur a le mérite de fournir un ordre de grandeur pour évaluer approximativement les bénéfices que tire le consommateur de l’usage d’un service. En 2012, le Boston Consulting Group sondait une multitude d’internautes à travers de nombreux pays pour connaître la valeur qu’ils attribuent aux services offerts par internet. Les participants ont été invités à se prononcer sur les activités et les biens de consommation auxquels ils seraient prêts à renoncer pendant un an pour profiter d’internet.

Pourcentage des individus prêts à renoncer à un élément clef de leur mode de vie pendant un an pour conserver internet
L’enquête s’est également penchée sur la somme que les individus seraient prêts à payer au maximum pour bénéficier d’internet. Selon les résultats de l’enquête, le Français moyen était prêt à payer 4788 dollars par an. Le surplus du consommateur correspondrait ici à 4453 dollars par an[[The Internet Economy In the G-20, The $4.2 Trillion Growth Opportunity, Boston Consulting Group, 2012]].
")
Évaluation des bénéfices annuels apportés par Internet dans certains pays sélectionnés (dollars)
Peut-on tenter d’attribuer la part de ce bénéfice à un service comme Facebook ? On peut dans un premier temps noter que, dans un pays comme la France, le temps passé sur Facebook correspond à un peu moins d’un dixième du temps total passé sur internet.
En effet, selon le CRÉDOC, chaque Français passait en moyenne 13 heures par semaine sur internet en 2012[[http://www.credoc.fr/pdf/Rapp/R333.pdf]]. Cela faisait 677.82 heures par an. Toujours en 2012, le temps mensuel moyen passé sur Facebook par un utilisateur français s’élevait à 5 heures et 18 minutes par mois, soit 63,6 heures par an[[http://www.zdnet.fr/actualites/facebook-en-france-26-millions-d-utilisateurs-actifs-plus-de-5-heures-par-mois-39774160.htm]].
Ces 63,6 heures peuvent être mises en perspective avec les 5,32 dollars de chiffre d’affaires que Facebook générait en 2012 pour chaque utilisateur dans le monde. En Europe, ce chiffre s’élevait à 5,91 dollars (contre 13,58 dollars en Amérique du Nord)[[Facebook Annual Report 2012]].
Il est difficile, à partir de ces données, de chiffrer les bénéfices perçus par les utilisateurs. Les méthodes utilisées ne sont pas consensuelles. Par exemple, une étude de 2010 conduite par le cabinet McKinsey & Compagny pour le compte de la section européenne de l’Interactive Advertsing Bureau (IAB Europe) a procédé en sondant les internautes. L’étude soutenait qu’en moyenne, un ménage composé de deux personnes était prêt à payer 38 euros par mois pour accéder à des services de communication comme les réseaux sociaux. Une autre méthode consiste à mettre un prix sur l’heure passée sur internet, comme l’ont fait les chercheurs Erik Brynjolfsson et Joo Hee Oh dans le cadre de travaux menés pour le Massachusetts Institute of Technology[[“The Attention Economy: Measuring the Value of Free Goods on the Internet,” Erik Brynjolfsson, and JooHee Oh, July, 2012]]. Si pour 677,82 heures passées sur internet en 2012, les Français étaient prêts à payer annuellement 4788 dollars, alors une heure peut s’évaluer en moyenne à 7,1 dollars.
Pour 63,6 heures annuellement passées sur Facebook, les Français seraient donc prêts à payer au maximum 451,6 dollars. En déduisant les coûts effectifs liés à l’accès internet pour 63,6 heures (31,4 dollars), on obtient un surplus de consommateur de 420,2 dollars par an, soit 35 dollars par mois.
Précisions que ces calculs sont imparfaits. Cependant, ils permettent d’obtenir un ordre de grandeur quant aux bénéfices générés par les services informatiques. L’idée que les services disponibles sur internet génèrent des bénéfices inestimables pour les consommateurs tend à être corroborée par d’autres études, notamment citées par le magazine britannique The Economist[[« Net benefits », The Economist, 9 mars 2013]]. L’étude de 2010 précédemment citée et conduite par le cabinet de conseil McKinsey & Compagny pour le compte de l’IAB Europe, agrégeant le surplus des producteurs et des consommateurs de services financés par la publicité et les données personnelles dans certains pays et aux États-Unis, soulignait que les clients captaient 100 milliards d’euros de surplus, soit 85% du surplus généré par cette industrie. Sans nier les désagréments et autres concessions liés à l’interruption publicitaire et à la vie privée, le rapport souligne néanmoins que plus de 80% des utilisateurs valorisent beaucoup plus les services offerts par internet que les concessions faites en matière de vie privée et de publicité. En moyenne, « pour chaque euro qu’un utilisateur est prêt à dépenser pour limiter les désagréments liés à la perte de vie privée et à la publicité, il évalue à 6 euros les bénéfices qu’il reçoit pour l’usage des applications web financées par la publicité ».
Notons que toutes les études précitées ont été produites entre 2006 et 2012. L’enrichissement des contenus disponibles sur la toile, les gains de productivité et les baisses de coûts relatifs à l’accès aux technologies de l’information et de la communication conduisent à penser que les chiffres présentés dans ce paragraphe sous-estiment les bénéfices actuels induits par l’usage de ces services.
Rien ne permet donc d’affirmer que les échanges entre les utilisateurs et les plateformes souffriraient d’un quelconque déséquilibre commercial.
+La question des asymétries d’information et de l’opacité des conditions d’utilisation+
Certains objectent que le consommateur n’est pas en mesure d’évaluer correctement l’équilibre commercial qui prévaut entre lui et la plateforme. Deux raisons sont régulièrement évoquées : le secret des méthodes de traitement des données et l’opacité des conditions d’utilisation. Mais ces deux arguments sont discutables.
Les asymétries d’information
Tout comme les secrets industriels ne compromettent pas le commerce de marchandises, les secrets propres au traitement des données ne constituent pas un obstacle au bon fonctionnement du commerce en ligne dès lors qu’ils sont tolérés par les utilisateurs. Comme l’équilibre des relations commerciales, seul le processus concurrentiel peut révéler le niveau acceptable de transparence en matière de traitement des données aux yeux des consommateurs.
Comme l’énonce l’économiste Caleb S. Fuller : « dans la mesure où l’incertitude et les asymétries d’information obscurcissent la nature des informations collectées, elles constituent aussi un élément non-pécuniaire du prix payé par le consommateur »[[Fuller, C.S. Eur J Law Econ (2018) 45: 225. https://doi.org/10.1007/s10657-017-9563-6]]. Ce prix est librement convenu entre la plateforme et ses utilisateurs dans la mesure où ces derniers peuvent tout à fait le refuser. Il suffit par exemple qu’ils considèrent le niveau d’opacité d’une entreprise inacceptable au regard des services rendus. Dans ces conditions, ils n’échangeront pas avec la plateforme en question.
Au contraire, un entrepreneur qui opère sur un marché où la transparence des conditions de traitement est un critère décisif de compétitivité doit faire de celle-ci un argument commercial. Il dispose pour cela de plusieurs moyens : communiquer sur ses pratiques et compter sur sa réputation et le crédit que lui accordent ses clients, inscrire ses pratiques dans ses conditions d’utilisation, ou recourir à des tiers de confiance chargés de contrôler et de certifier ses pratiques pour faire valoir leur sincérité auprès du public. À titre d’exemple, la CNIL décerne ses propres labels. Le RGPD prévoit la possibilité pour les autorités de contrôle de protection des données personnelles d’accréditer des organismes privés de certification.
En Europe, le label European Privacy Seal (EuroPrise) a l’ambition de délivrer un certificat pan-européen pour attester la conformité d’une organisation aux prescriptions de la législation européenne en matière de protection des données. Aux États-Unis, l’entreprise Trustarc fournit également des labels pour certifier qu’une organisation respecte certains standards (les directives de l’OCDE, Privacy Shield, les principes de la coopération économique pour l’Asie-Pacifique en matière de vie privée, les prescriptions de la Federal Trade Commission, etc.).
Ces exemples montrent que de nombreux moyens existent pour pallier les asymétries d’information qui définissent les rapports entre les utilisateurs et les plateformes. Il est important de rappeler que seules les préférences des utilisateurs permettent de révéler au cas par cas le niveau de transparence désirable pour les traitements des données personnelles.
Les conditions d’utilisation
Le second argument régulièrement soulevé pour nier le caractère mutuellement profitable des relations entre les utilisateurs et leurs plateformes est l’opacité des conditions d’utilisation. La longueur et la technicité des conditions d’utilisation seraient telles que le consentement des consommateurs s’en trouverait nécessairement vicié. Mais cet argument fait l’impasse sur les raisons qui expliquent que les utilisateurs acceptent de contracter sans avoir une idée précise de leurs engagements contractuels.
L’intérêt, pour un utilisateur, de lire les conditions d’utilisation d’une plateforme est de s’assurer que les obligations qui naissent du contrat d’utilisation ne seront jamais excessives à ses yeux. Or si cette démarche est très coûteuse en temps, ses bénéfices sont incertains. Plusieurs raisons expliquent cette incertitude. Certaines d’entre elles sont citées par une récente étude réalisée pour le compte de la Commission européenne[[Elshout, Maartje and Elsen, Millie and Leenheer, Jorna and Loos, Marco and Luzak, Joasia, Study on Consumers’ Attitudes Towards Terms Conditions (T&Cs) Final Report (September 22, 2016). Report for the European Commission, Consumers, Health, Agriculture and Food Executive Agency (Chafea) on behalf of Directorate-General for Justice and Consumers.. Available at SSRN: https://ssrn.com/abstract=2847546]]. Une explication intéressante est qu’il existe des moyens alternatifs pour s’assurer que des conditions d’utilisation ne génèrent pas de coûts « excessifs ».
La réputation est un premier indice. Selon cette perspective, il est peu probable qu’un service utilisé par des millions d’individus comportent des clauses excessivement contraires aux intérêts de ces derniers, auquel cas le service serait moins populaire. Une autre explication est que dans la plupart des pays, les conditions d’utilisation sont soumises à des lois impératives qui protègent le consommateur de toute clause jugée « abusive ». L’individu délègue au législateur la mission de s’assurer que les conditions d’utilisation seront conformes à ses intérêts. Notons que cette délégation peut aussi se faire, en l’absence de lois impératives, au profit de tiers de confiance informels, comme des associations de consommateurs, des journalistes ou des leaders d’opinion. Ainsi, en dépit de la technicité des conditions d’utilisation, le consommateur s’assure de la fiabilité d’une relation contractuelle avec un prestataire, aussi longtemps qu’il ne sent pas lésé et qu’aucun scandale public n’est venu affaiblir la réputation de l’entreprise. Cette solution nous paraît plus respectueuse des volontés de toutes les parties contractantes.
II – La libre exploitation des données et ses restrictions
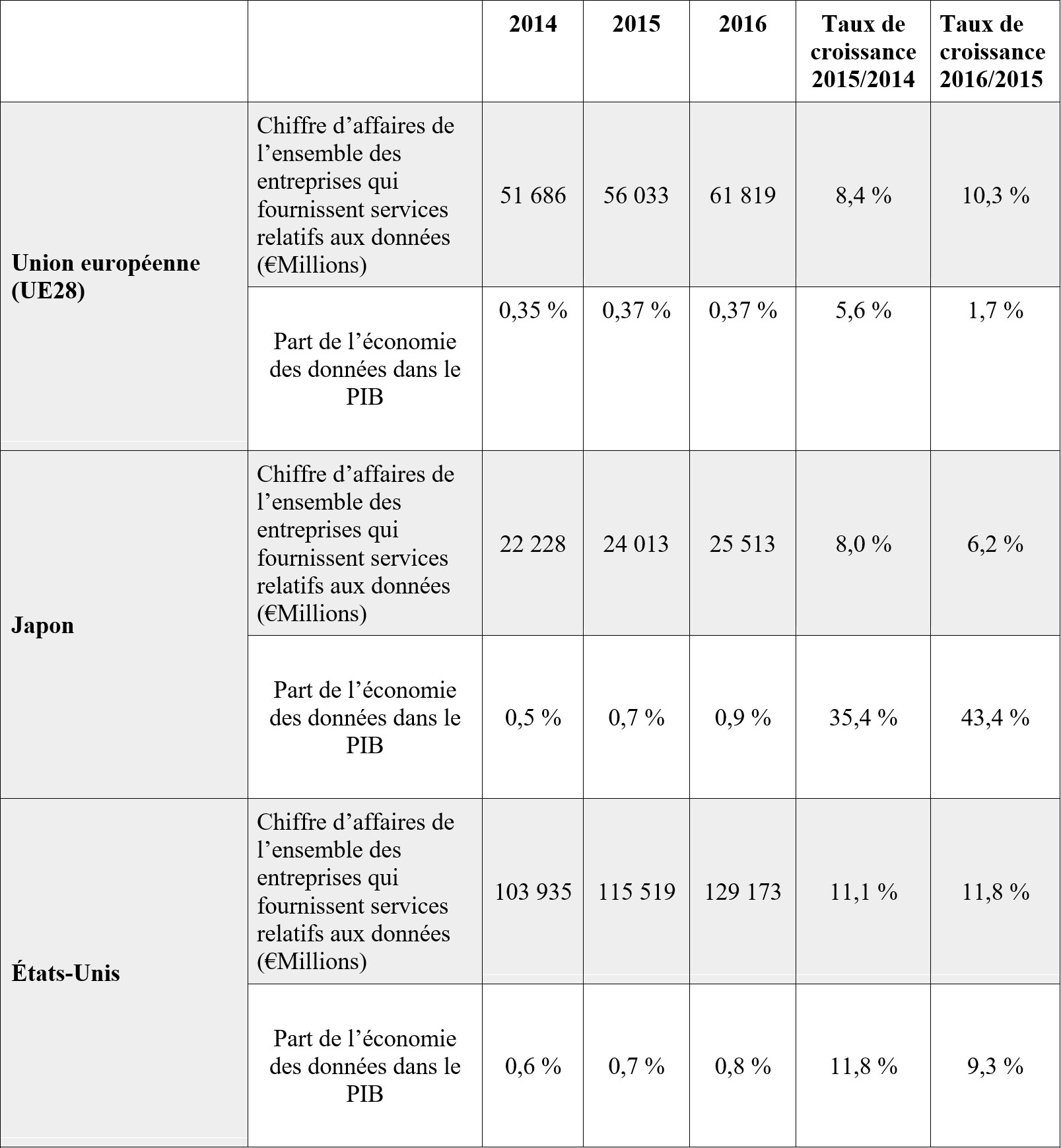
Selon un rapport publié en février 2017 par la Commission européenne, le chiffre d’affaires généré par les entreprises basées en Europe qui fournissent des services en lien avec les données s’élevait à 62 milliards d’euros en 2016. Ce chiffre peut être mis en perspective avec celui qui est affiché dans d’autres régions du monde comme les États-Unis (129 milliards d’euros) et le Japon (25 milliards d’euros), comme le montre le tableau suivant.
Le commerce du traitement des données a indéniablement favorisé l’apparition de services utiles pour les consommateurs dans de nombreux secteurs.
Par exemple, l’usage des données personnelles à des fins publicitaires permet aux producteurs de réduire le coût de leurs campagnes tout en augmentant leur efficacité. Pour les consommateurs, il permet de révéler l’existence de produits susceptibles de les intéresser. Tout en améliorant la rencontre entre l’offre et la demande, le traitement des données à des fins publicitaires finance également de nombreux services aujourd’hui valorisés par les consommateurs sans lesquels leur existence serait peu probable.

D’autres industries que celle de la publicité peuvent utiliser le traitement des données personnelles pour servir leurs intérêts ainsi que celui de leurs clients.

Malheureusement, le traitement des données peine à réaliser son potentiel. De nombreuses réglementations viennent l’entraver. Dans un article publié par le magazine américain Foreign Affairs, Susan Lund et James Manyika, tous deux affiliés au McKinsey Global Institute, identifient trois types de restrictions à l’exploitation des données. Les premières restrictions concernent les actes de censure. Les secondes portent sur la localisation et le transfert de données (en anglais « data localisation requirements »). Les troisièmes sont relatives aux règlementations sur la vie privée. Seules les deux dernières seront traitées.
+A – Les restrictions en matière de localisation de données+
Comme leur nom l’indique, ces restrictions obligent les opérateurs à stocker certaines informations dans les juridictions désignées par les États qui les imposent. Dans un article publié par l’European center for International political economy, la chercheuse Martina F. Ferracane répertorie une variété de restrictions émises par différents gouvernements, notamment européens[[Martina F. Ferracane, Restrictions to Cross-Border Data Flows: a Taxonomy, ECIPE WORKING PAPERS, November 2017]]. Selon elle, l’Allemagne impose par exemple aux entreprises de stocker certains documents comptables sur son territoire. Le Luxembourg impose aux institutions financières de traiter leurs données au sein de ses frontières, à quelques exceptions près pour les entités qui appartiennent à un groupe international. D’autres pays comme la Bulgarie et la Pologne imposent au secteur des jeux de hasard de stocker leurs données à l’échelle nationale.
Le problème de ces restrictions est qu’elles ont un coût. Elles obligent en effet les entreprises à construire ou à louer des serveurs redondants, ce qui nuit à l’adoption d’économies d’échelle au détriment de leur rentabilité et de leur compétitivité. Une étude du Leviathan Security Group, une entreprise spécialisée dans le risk management et la sécurité des systèmes d’information, estime que ces restrictions peuvent augmenter de 30 à 60 % les coûts de l’usage de services informatiques dans les pays où elles sont appliquées[[Quantifying the Cost of Forced Localization, Leviathan Security Group, June 2015]]. Une autre étude publiée par un organisme affilié au Parlement européen estimait que ces entraves pouvaient générer jusqu’à 63 milliards d’euros de pertes par an pour l’économie européenne[[Zsolt Pataki, The Cost of Non-Europe in the Single Market, European Parliamentary Research Service, September 2014]].
Les gouvernements justifient généralement ces mesures à l’aide de plusieurs arguments plus ou moins discutables.
Le premier argument est sécuritaire. En localisant les serveurs dans certaines juridictions, les opérateurs réduiraient l’exposition des internautes au risque de piratage et d’espionnage que feraient notamment peser les régimes autoritaires adeptes de la surveillance de masse. Il est certes dans l’intérêt des individus que leurs données ne tombent pas entre de mauvaises mains. L’exemple terrifiant de la Chine qui utilise le Big Data pour renforcer sa police politique contre ses propres citoyens mériterait que les opinions publiques et le personnel politique se préoccupent davantage des dangers d’une mauvaise utilisation des données personnelles. Dans l’hypothèse où la localisation des données diminuerait l’exposition des utilisateurs à la prédation des régimes autoritaires, l’argument sécuritaire mériterait d’être très sérieusement considéré. Cependant, la plupart des experts en cyber-sécurité estiment que la localisation d’un serveur n’a aucun effet sur sa vulnérabilité à la cybercriminalité ou à la surveillance.
Le second argument fait appel à des motivations protectionnistes concernant la création d’emplois. En obligeant les entreprises à installer leurs serveurs à l’échelle nationale, on créerait plus d’emplois dans la maintenance de ces serveurs. Mais cet argument est là encore discutable. Hormis le fait que la création d’emplois n’est jamais une fin en soi (elle n’est qu’un moyen de créer des services utiles), les data centers créent en créent peu dans la mesure où ils sont très largement autonomes. L’article de Susan Lund et James Manyik publié sur Foreign Affairs prend ainsi en exemple le gigantesque centre de données de Facebook en Suède qui n’emploie que 150 personnes. Soit un technicien pour 25 000 serveurs. Au contraire, en faisant peser d’importants coûts fixes sur les entreprises, les restrictions en matière de localisation amputent les possibilités d’investissements et donc les créations d’emplois plus utiles tout en répercutant une partie de ces coûts sur le consommateur de services informatiques.
Le troisième argument soulève des préoccupations répressives. Les gouvernements préfèrent que les serveurs d’une entreprise se situent à l’intérieur de leurs frontières dans l’hypothèse où il faudrait les fermer pour appliquer des sanctions. Cet argument soulève des questions d’état de droit dans la mesure où elles augmentent l’exposition des individus à une violation de leur liberté de communication.
Consciente des coûts que constituent ces législations protectionnistes, l’Union européenne tente de les affaiblir à l’intérieur de ses frontières. L’article premier du règlement général sur la protection des données personnelles (RGPD) interdit aux États d’imposer des restrictions au sein de l’Union pour des motifs liés à la protection des personnes physiques à l’égard du traitement des données à caractère personnel. Le projet de règlement «vie privée et communications électroniques» (e-Privacy) comporte des éléments similaires. Son article 1 dispose que : « Le présent règlement garantit la libre circulation des données de communications électroniques et des services de communications électroniques au sein de l’Union, qui n’est ni limitée ni interdite pour des motifs liés au respect de la vie privée et des communications des personnes physiques et morales et à la protection des personnes physiques à l’égard du traitement des données à caractère personnel. ». Enfin le projet de règlement relatif à la libre circulation des données non personnelles prévoit lui aussi que les États s’abstiennent de restreindre la localisation du traitement ou du stockage de données, sauf pour des motifs sécuritaires.
Cependant, si l’Union européenne affiche à juste titre l’ambition de restreindre le protectionnisme numérique à son échelle, elle le reproduit malheureusement vis-à-vis des pays tiers. Par exemple, le RGPD conditionne le transfert de données dans des pays tiers à l’inscription de ces derniers à une liste blanche. Ces pays accèdent à cette liste blanche s’ils offrent « un niveau de protection adéquat » de vie privée. À défaut du respect de ce critère, le responsable du traitement est sommé de s’imposer de lourds standards pour compenser les carences du pays tiers dans lequel il stocke les données personnelles de ses clients. Le problème de cette disposition est qu’elle concède un très grand pouvoir discrétionnaire aux organisations gouvernementales, ce qui ouvre la porte à toutes les dérives protectionnistes en l’absence de critères objectifs pour déterminer ce qu’est un « niveau de protection adéquat de vie privée ».
L’Union européenne devrait abandonner ce deux-poids-deux-mesures vis-à-vis des pays tiers. La logique libre-échangiste qu’elle applique à l’intérieur de ses frontières doit être étendue à tous les pays du monde pour permettre à l’industrie des nouvelles technologies de l’information et de la communication d’optimiser ses coûts. Cette extension doit prévaloir indépendamment des différences de standards qui affectent la protection de la vie privée. Ce n’est pas à l’Union européenne de déterminer les standards les plus pertinents en matière de protection de la vie privée. Ces standards doivent émerger d’un processus concurrentiel libre.
+B – Le problème des normes de confidentialité impératives+
Les normes impératives de confidentialité constituent aujourd’hui les obstacles les plus redoutables au déploiement d’une industrie compétitive du big data. Ces règlementations limitent les possibilités de traitement des données personnelles. C’est-à-dire qu’elles encadrent la collecte, l’enregistrement, l’organisation, la conservation, la transmission et l’usage de données personnelles.
Ces restrictions partaient originellement de préoccupations légitimes : limiter le risque que les gouvernements faisaient peser sur les libertés individuelles en amassant toujours plus de données sur leurs administrés. En Europe, la législation française est régulièrement considérée comme pionnière en matière de protection des données personnelles. La naissance de la CNIL et de la loi informatique et libertés fait suite au scandale lié au « Système automatisé pour les fichiers administratifs et le répertoire des individus » (SAFARI) révélé par le journaliste Philippe Boucher en 1974. Il s’agissait d’un projet gouvernemental destiné à établir une base de données centralisée des citoyens français. Sous la pression de l’opinion publique, il a été abandonné.
Les préoccupations liées à la sauvegarde de la vie privée ont cependant abouti à l’adoption d’une réglementation universelle, concernant aussi bien les administrations publiques que le secteur privé. Cette confusion repose sur l’idée que le traitement des données personnelles par les États et les entreprises commerciales ferait peser sur les libertés publiques un risque similaire. Rien n’est plus faux que cette affirmation.
Mettre les États et les entreprises sur le même plan n’est pas pertinent pour la raison que la nature de ces deux types d’organisations diffère. La singularité des États tient au fait que le monopole de la force qu’ils détiennent présente un danger pour les libertés publiques. C’est en raison de ce danger qu’il est risqué de leur conférer du pouvoir et a fortiori de les laisser traiter des données personnelles librement. C’est d’ailleurs la reconnaissance de la dangerosité particulière des États vis-à-vis des libertés individuelles qui fonde toute la tradition constitutionnelle occidentale depuis le 18ème siècle.
Différemment, les entreprises ont une finalité essentiellement commerciale. En traitant les données personnelles de leurs utilisateurs, des entreprises comme Google, Facebook ou Amazon ne peuvent avoir ni la volonté ni la capacité de persécuter ou d’enfermer leurs clients dans une prison. Le traitement des données personnelles à des fins commerciales implique que les entreprises doivent impérativement trouver les moyens de satisfaire les besoins de leurs clients sans quoi elles ne sont pas rentables et disparaissent. Le traitement des données à des fins commerciales ne recèle donc pas les mêmes dangers. Bien sûr, le fait que les entreprises présentent un faible risque sécuritaire ne signifie pas qu’il n’existe pas d’inquiétudes légitimes en matière de confidentialité. Il reste à savoir si ces inquiétudes justifient une réglementation étatique comme le RGPD ou e-Privacy.
Le problème de cette réglementation étatique est qu’elle puise son existence dans l’idée contestable que l’on pourrait définir de manière objective et centralisée un niveau minimum acceptable de confidentialité pour tous les consommateurs de services numériques. Or la notion même de niveau minimum acceptable de confidentialité est par essence subjective. Elle dépend de l’expérience intime de l’utilisateur avec son opérateur, des services rendus en contrepartie ou encore du type de données traitées. C’est parce que les attentes en matière de confidentialité sont multiples et variées qu’il serait plus optimal de permettre à chacun de faire le choix d’un marché libre de la confidentialité à défaut duquel choix seulement devraient s’appliquer des standards publics.
On entend par « marché libre de la confidentialité » un processus où le niveau acceptable de confidentialité pour chaque individu et chaque service serait le fruit d’une libre confrontation entre l’offre et la demande. Ce marché existe déjà. Prenons l’exemple des services de messagerie électronique. Certains seront à l’aise avec l’idée que des robots analysent leurs messages à des fins publicitaires en contrepartie d’un service de messagerie performant, offrant un vaste espace de stockage, le tout sans contrepartie pécuniaire. Ils utiliseront dans ce cas probablement des logiciels comme Google Mail. Au contraire, d’autres seront plus réticents à partager leurs données et exigeront un niveau plus strict de confidentialité. Ils utiliseront donc des applications comme Protonmail pour ne citer qu’un exemple parmi la palette de services existants sur le web. Il faut cependant avoir à l’esprit que cette confidentialité a toujours un prix. Ces services confidentiels, à défaut de pouvoir se rémunérer sur les données personnelles de leurs utilisateurs, exigeront le plus souvent des contreparties pécuniaires.
Édicter des standards impératifs en matière de confidentialité dans les relations commerciales n’a donc pas beaucoup d’utilité, sinon subsidiairement, lorsque le marché offre suffisamment de normes de confidentialité là où il existe une véritable demande pour celles-ci. Car, alors qu’elles ne protègent même pas toujours bien les individus, les normes publiques de confidentialité impératives imposées au traitement des données à des fins commerciales peuvent générer des coûts excessifs pour des entreprises qui auraient pu s’en passer en raison de l’absence de demande de la part de leur clientèle. Ces coûts sont d’autant plus redoutables que l’industrie du numérique porte une spécificité trop souvent occultée. Son efficacité est en effet étroitement liée à l’existence de larges économies d’échelle. Tout coût fixe arbitrairement imposé entrave l’arrivée de nouveaux entrants sur le marché et restreint la concurrence. Enfin, si l’on se souvient que, pour de nombreuses entreprises, le traitement des données personnelles n’est ni plus ni moins que le prix du service rendu, alors il faut envisager les normes de confidentialité impératives comme des mesures de contrôle des prix, avec toutes les conséquences que ces mesures impliquent. Cela ne peut aboutir qu’à une offre de services en data plus rare et moins compétitive.
De nombreuses études font état d’effets pervers générés par la réglementation sur la vie privée. On compte parmi ces effets pervers :
– l’augmentation des coûts de recherche des entreprises et des consommateurs[[Varian, H. R. (1997). Economic aspects of personal privacy. In Privacy and Self-Regulation in the Information Age. US Department of Commerce.]]
– l’affaiblissement de l’innovation ainsi que de la capacité des consommateurs et des firmes à se rencontrer[[Lenard, T. M., & Rubin, P. H. (2009). In defense of data: information and the costs of privacy. Technology Policy Institute Working Paper 9–44]]
– l’affaiblissement de l’efficacité de la publicité en ligne[[Goldfarb, A., & Tucker, C. E. (2011). Privacy regulation and online advertising. Management Science, 57(1), 57–71.]]
– l’affaiblissement des incitations à investir dans le secteur de la publicité en ligne et plus généralement des services de l’information financés par cette même publicité[[Lerner, J. (2012). The impact of privacy policy changes on venture capital investment in online advertisingcompanies. Analysis Group, 1–27.]].
– l’établissement de barrières à l’entrée dans le secteur numérique qui entravent la concurrence et qui réduisent la possibilité de contester les positions dominantes[[Campbell, J., Goldfarb, A., & Tucker, C. (2015). Privacy regulation and market structure. Journal of Economics and Management Strategy, 24(1), 47–73.]].
La réglementation relative à la vie privée ne soulève pas seulement des préoccupations économiques. Elle pose également des questions philosophiques sur les atteintes qu’elle génère à l’encontre de la liberté d’expression, la liberté des communications et la liberté d’entreprendre. En effet, la réglementation sur la vie privée s’apparente à une interdiction de traiter les informations personnelles au-delà du périmètre défini par le législateur. Si on l’appliquait avec cohérence, il faudrait interdire à n’importe quel particulier de posséder un fichier Word comportant le patronyme ainsi que des éléments sur le physique et les goûts de son voisin en dehors des critères de licéité du traitement posés par la législation. Bien entendu, le législateur ne va pas jusque-là. Il réserve les restrictions aux traitements qui comportent une finalité professionnelle. Il est conscient qu’une extension de ces restrictions aux traitements particuliers serait impossible à mettre en œuvre à moins de basculer dans une société policée.
La législation doit donc reconnaître à chacun le droit de disposer de ses données librement. Sur le plan commercial, soit la personne doit manifester la volonté de conserver la confidentialité de ses données, et le cas échéant payer différemment les services qu’elle aurait eu en échange de ces données, soit elle doit autoriser l’usage de ses données et, dans ce cas, choisir le mode et le degré de protection et de confidentialité qu’elle souhaite.
Au surplus, il faut arrêter de penser qu’il faut toujours, et toujours plus, protéger les gens malgré eux. Au contraire, il faut les rendre responsables de la gestion d’eux-mêmes et on y parviendra mieux en leur permettant d’avoir le choix de protéger plus ou moins leurs données ou de payer.
Il faut également admettre que certaines données sont publiques et qu’il ne convient donc pas d’en limiter la diffusion sinon de sanctionner des utilisations abusives ou malveillantes. Dès lors que les individus auraient le droit de demander l’application d’une norme de confidentialité, privée ou publique, à leur prestataire de services, et que celui-ci aurait le droit de refuser de délivrer un service gratuit à celui qui ne voudrait pas qu’on utilise ses données, restreindre les capacités des entreprises à traiter les informations personnelles des individus par une réglementation s’apparenterait davantage à une nouvelle forme de censure qu’à une protection des libertés publiques.
Certes, il peut arriver que certains prestataires de services aient des attitudes malveillantes, frauduleuses, dolosives… et dans ce cas ils doivent bien entendu être condamnés. Les particuliers devraient pouvoir d’ailleurs faire appel à des tiers de confiance, privés, qui garantiraient le sérieux et le respect des normes proposées par les prestataires de services. Mais sauf cas particuliers, les dispositions actuelles du code pénal permettent déjà de condamner les entreprises de services pour leurs comportements malhonnêtes, déloyaux… Il nous paraît donc souhaitable qu’à défaut d’accord de confidentialité passés avec leurs clients auxquels elles auront du le proposer, les entreprises soient libres de traiter les données des individus dans les limites des prescriptions pénales destinées à sanctionner des comportements malveillants.
Les standards commerciaux en matière de confidentialité doivent donc être facultatifs. Ils doivent être le fruit des arrangements contractuels entre les producteurs et les consommateurs de services numériques. La France et l’Europe doivent adopter une politique de la confidentialité essentiellement basée sur la régulation par la concurrence en s’inspirant notamment de la doctrine qui a longtemps gouverné le marché de la confidentialité aux États-Unis. Le rôle des régulateurs comme la CNIL doit donc être revu. Plutôt que de se comporter comme une autorité administrative chargée d’appliquer une réglementation arbitraire, la CNIL pourrait se transformer en un tiers de confiance privé chargé de réduire les asymétries d’information en auditant et en certifiant les normes de confidentialité auxquelles les producteurs et les consommateurs adhèreraient volontairement.
CONCLUSION
La prolifération des données et la capacité à les traiter toujours plus pertinemment à des fins commerciales constituent une formidable opportunité d’améliorer la condition des êtres humains dans une multitude de secteurs d’activité. La présente étude s’est attachée à montrer que le commerce du traitement des données est globalement un jeu à somme positive. Son succès et dans une moindre mesure les études marketing révèlent que les avantages qu’en tirent les utilisateurs sont infiniment supérieurs aux concessions faites en matière de vie privée, sans quoi il n’aurait pas connu un développement aussi fulgurant.
Le commerce du traitement des données constitue la source principale de financement pour de nombreux services en ligne. Sans lui, de nombreux services particulièrement valorisés par les consommateurs disparaîtraient dans des domaines aussi divers et variés que l’information, les communications ou encore les moteurs de recherche horizontaux et verticaux. Rien ne permet donc d’affirmer que les transactions numériques souffriraient de déséquilibres commerciaux. Il est de la responsabilité des utilisateurs qui accordent de l’importance aux conditions d’utilisation de s’informer sur le fonctionnement des services qu’ils consomment, quitte à s’appuyer sur des leaders d’opinion, vulgarisateurs ou autres tiers de confiance pour s’affranchir des obstacles que la technicité du fonctionnement des plateformes fait peser sur leur compréhension.
Les gouvernements doivent se contenter d’abolir tous les obstacles au déploiement d’une industrie compétitive du Big Data. Les efforts de l’Union européenne pour abolir les restrictions en matière de localisation des données doivent être salués. Ils doivent cependant être poursuivis à l’échelle internationale sans être dénaturés par un processus d’harmonisation des normes de confidentialité. Seule la concurrence des normes peut révéler le niveau adéquat de confidentialité pour chaque service et chaque utilisateur.
Les normes impératives de confidentialité constituent les obstacles les plus redoutables pour le développement du commerce du traitement des données personnelles. Cette réglementation doit laisser place à une définition contractuelle des normes de confidentialité pour que celles-ci puissent correspondre aux besoins des producteurs et des consommateurs de services numériques. Les préoccupations légitimes des consommateurs doivent donc être satisfaites par des standards auxquels les organisations et les consommateurs adhèreraient volontairement.
Les normes de confidentialité doivent donc être facultatives. Les missions des autorités de contrôle doivent être revues. La CNIL doit être privatisée pour devenir un tiers de confiance de droit commun opérant sur un marché de l’audit et de la certification des politiques de confidentialité ouvert à la concurrence. Ces tiers de confiance pourront vendre leurs services aux entreprises lorsqu’il existe une véritable demande en vue de réduire les asymétries d’information. Seul ce processus peut garantir une régulation conforme aux intérêts de chacun.
